こんにちは。takanoです。
ブログを始めて 1 年ぐらい経ったのですが、毎回テーマが大きめだったので、たまに過去記事に追記する以外にはネタが枯渇しています。
というわけで、大きめテーマ SEO シリーズの締めくくりとして新任担当者向けの技術用語集を作ってみました。
SEO に取り組むうえで、エンジニアと話す機会も多いと思うので、その際に困らないように概念だけでも理解できるような解説をしています。
検索についてというより、その手前のものをピックアップしたので Web に関わる業務の人であれば参考になるものがあるかもしれません。
(検索についての専門用語はGoogle の公式ヘルプがあるので省きました)
なお、本当に何も知らない方になんとなく雰囲気をつかんでもらうための解説なので、ガチの技術者の方は参考にならないと思います。
(私もエンジニアではないので、どうかマサカリは投げないでください)
Web ページ関連
まずは Web ページを構成する、基本の 3 点セットからいきましょう。
この辺りは他の解説も多いので、あまり細かく書かずにさらっといきます。
なお、これらはそれぞれ別な「言語」です。異なる「言語」なので、例えば日本語と英語のように別々の文法があります。
HTML
HyperText Markup Language(ハイパーテキスト・マークアップ・ランゲージ)の略で、Markup が「目印をつける」という意味です。カッコいいですね。
それぞれに役割が違う「タグ」を使って、Web ページの構造を定義できる「文書」ファイルです。
「文書」なので、JavaScript でも Web ページ自体を参照するときに "document" を使います。
また、マークアップにより定義された構造をブラウザ等が解析し、 DOM(Document Object Model)として利用します。
それぞれのタグによって使える「属性」があり、細かい挙動や参照先などを指定できます。
(a タグの href 属性とか、img タグ の alt 属性などです)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>テスト</title> <meta name="description" content="これはテストページです"> </head> <body> <h1>見出し</h1> <img src="画像のソース URL" alt="代替テキスト"> <p> 段落 <a href="リンク先">テキスト</a> テキストテキストテキスト </p> </body> </html>
CSS
Cascading Style Sheet(カスケーディング・スタイルシート)の略です。カッコいいですね。
HTML ファイルだけでは、ただの文書なので見た目が簡素です。
そこに色や文字の大きさ、余白などの装飾をするのが CSS の役割です。
head タグの中で外部ファイルとして読み込みます。
<head> <meta charset="utf-8"> <title>テスト</title> <meta name="description" content="これはテストページです"> <!-- 外部ファイルで読み込むのが CSS --> <link rel="stylesheet" href="/css/style.css"> <!-- style タグで直接 HTML 内に書くことも可能 --> <style> /* その場合は style タグ直書き(じかがき)と言います */ /* やり過ぎるとメンテナンスしづらいので嫌われます */ </style> </head> <!-- style 属性で HTML タグに直接指定も可能 --> <body style="background-color:#FFFFFF;"> <!-- これは style 属性直書き(じかがき)と言います --> <!-- やっちゃうと周囲に忌み嫌われるので避けましょう -->
JavaScript
これはそのままです。JS と略す場合もありますね。Java と略すとエンジニアに圧倒的に舐められます。(Java は全く別な言語の名前なので)
HTML と CSS だけでは実現できない動きを Web ページに加えることができます。
アクセス解析や広告のコンバージョン計測でも利用されています。
<head> <meta charset="utf-8"> <title>テスト</title> <meta name="description" content="これはテストページです"> <!-- CSS みたいに外部ファイルとして読み込んだり --> <script src="/js/javascript.js"></script> <!-- 直接 HTML 内に書くことも可能 --> <script> /* これも直書き(じかがき)と言います */ </script> </head>
プログラム関連
さて、ここからが本題ですね。エンジニアと話すうえで概念だけでも知っておくと何かと役に立つ用語たちです。
言語の種類によらず(たぶん)ある程度共通しているものをピックアップしています。
関数
まずは関数(かんすう)です。前段に出てきた JavaScript を例にしてみましょう。
/* 好きな名前を付けられる */ function sample() { /* この中にやりたいことを書く */ }
関数と書くと難しいですが、何らかやりたい処理をまとめてパッケージにしたものと考えると良いと思います。
自分で付けた名前があれば、その名前を使って後で呼び出すことが可能です。
<!-- ボタンを押すと実行される --> <button onClick="sample()"> ボタン </button>
この例の場合は、ボタンを押すのをトリガーに実行されるようにしてあります。
こうして、何かを引き金に実行されることを「発火する」と言います。
引数
/* 括弧の中が引数 */ /* 名前は好きに付けられる */ function sample(button) { /* その名前で、この中で使えるようになる */ alert(button.id); }
<!-- 実行の際に値をセットしてあげる --> <!-- 何も無いと引数は空になる --> <button id="button" onClick="sample(this)"> ボタン </button>
引数は、「いんすう」ではなく「ひきすう」と読みます。
関数をより便利にするためのオプション的な存在で、何かを引数に設定することを「渡す」と言います。
上記の例では、クリックされた際にボタン要素自体を渡しています。(JavaScript のそういう書き方です)
なので、ボタンをクリックすると sample という関数に ボタン要素自体が渡され、関数の中でボタン要素の id 属性が参照できるようになり、結果をアラート表示しています。(JavaScript のそういう書き方です)

ここまで書いて気付いたのですが、Excel 好きの方であれば、関数・引数の話は実感のある話と思います。
変数
次は変数(へんすう)ですが、ここでは分かりやすくするために以下のような例にしてみます。
function sample(button) { /* ボタンの id 属性を好きな名前で変数として定義 */ var id = button.id; /* 後で定義した名前で利用できる */ alert(id); }
そして、ボタンを 3 つに増やしてみました。
<!-- それぞれのボタンに異なる id 属性 --> <button id="button_a" onClick="sample(this)"> ボタン A </button> <button id="button_b" onClick="sample(this)"> ボタン B </button> <button id="button_c" onClick="sample(this)"> ボタン C </button>
ボタン C をクリックすると、ボタン C の id 属性がアラートされます。

この場合、button.id をそのまま使うのと差が無いですが、関数の中身が複雑な際は変数にしておくと便利な場合が多いです。
つまり変数とは、任意の名前で、場合により異なる値を利用可能にできるものですね。
GTM のデータレイヤー変数も、同じノリです。
変数に何か値を設定することを「代入する」と言いますが、開発の現場では単に「入れる」とか「突っ込む」とか言います。
「突っ込む」までいくと、こなれ過ぎた感じがするので、最初は「入れる」程度の表現にとどめておきましょう。
条件分岐
今度は条件分岐です。名前の通り、〇〇だったら××というように、条件に応じて処理を分岐させることができます。
以下の例では、代表的な if 文という書き方で分岐させています。
function sample(button) { var id = button.id; /* もし id が button_a だったら */ if (id == "button_a") { /* id をアラート */ alert(id); /* それか、もし id が button_b だったら */ } else if (id == "button_b") { /* ボタン要素内の文字列をアラート */ /* (JavaScript のそういう書き方です) */ alert(button.textContent); /* それ以外 */ } else { /* 自分で書いた文字列をアラート */ alert("今回の場合はボタン C"); } }
実行した結果はこんな感じです。

他の条件分岐の書き方では case 文などもありますが、個人的には以前記事で書いたデータポータルの計算フィールド以外では、ほとんど使ったことが無いので、軽微なフロントエンド開発までは if 文さえ使えれば困らないはずです。
配列
さて、次は配列です。これは概念としてすごく説明が難しいのですが、個人的にはリストの定義と思っています。
例えば、以下のように定義したリストから、男子だけ抜き出すと「田中くん」が取得できるのが配列です。
他にも配列の中にある要素の個数や並び順なんかも取得できますし、要素の追加や削除もできます。

GTM の実装をしたことがある方であれば、「データレイヤー変数」をご存じと思いますが、あれも配列ですよね。
最初に空(から)の状態で定義しておいて、後から送信したい内容を追加(push)していき、まとめて送信しています。
このように、色々な要素をまとめて扱うときに便利なのが配列です。
繰り返し処理
ループ処理とも呼びます。名前の通り色々な要素に対して繰り返し何らかの処理をすることです。
さっきの配列で考えてみると、以下のようなイメージです。
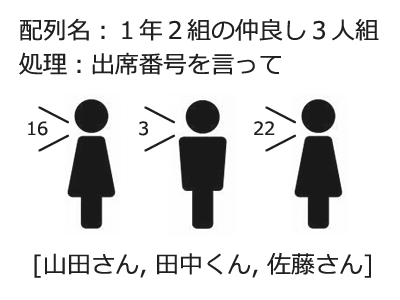
この際に、山田さん→田中くん→佐藤さんの順に合計 3 回処理が行われます。
例えばよくある EC やグルメ・不動産などの大きいサイトの一覧ページは、こうしたループ処理で生成されています。
オブジェクト
前段で仲良し 3 人組の出席番号を参照しましたが、こうした情報を取得するためには、あらかじめ定義されていることが必要です。
1 年 2 組のメンバーであれば、だいたい以下のような情報を持っているはずです。(本当はもっと細かいですが)
- 名前
- 年齢
- 性別
- 出席番号
- クラスの係
これらの定義が集まって、1 年 2 組の各メンバーを構成しています。
例えば山田さんだったら以下のようになります。
| 名前 | 山田花子 |
| 年齢 | 7歳 |
| 性別 | 女性 |
| 出席番号 | 16番 |
| クラスの係 | 学級委員 |
これもニュアンスが難しいのですが、個人的な感覚で言うと、このように情報の固まりで構成されているものをオブジェクトと呼びます。
EC サイトで言うと、商品詳細ページには「商品」というオブジェクトが、商品一覧ページには「商品リスト」というオブジェクトが存在します。
オブジェクトは入れ子にもなるので、「商品リスト」をループ処理して「商品」の名前や詳細ページのリンクを参照することが可能になるわけです。
また、サイト内の任意のページに対して、システム側で特定のオブジェクトを利用できるようにすることを「投げる」と言います。
例えば、商品詳細ページでその商品の属するカテゴリが取得できなければ、「親カテゴリ投げてください」とエンジニアに依頼すると設定してくれます。
データベース
前段までのように、オブジェクトが参照できたり、ループ処理などを行ってページを生成するサイトを動的サイトと呼びます。(データベース型サイトと言う派閥も)
それらを形作る情報の定義は、データベースに保存されています。
保存されている形式は、先ほど山田さんの例で紹介したような、表組みのイメージです。なので、情報の保存されている 1 つの固まりの単位を「テーブル(表)」と呼びます。
また、情報の 1 つずつの項目を「カラム(列)」と呼び、実際に情報が保存されている行を「レコード」と呼びます。
(先ほどの山田テーブルではスマホで見やすいように列と行が逆でしたので、謹んでお詫びします)
これらの保存されている情報をもとにオブジェクトが形成され、動的サイトを形作っていくわけですね。
また、解析などのために Web ページ側からデータベースに送信・保存する情報もあります。
SQL
最近よく聞く SQL とは、データベースの情報を扱う際に使う言語です。
文脈として分析などのためにデータベースからデータを抽出するときに使われることが多いですが、動的サイトでオブジェクトの定義などでプログラム内でも使われます。
Excel や BI ツールなどもあるので、大抵は覚えずに生活できると思いますが、数十万行を超えるデータを扱うケースが多くなると必要になるかなというイメージです。
正規表現
ものすごくざっくり書くと、メタ文字と呼ばれる記号を使って下記2つのことをして、それによってある文字の集まりから特定のパターンを表現することです。
- 文字列の定義
- 繰り返しの指定
続きは以前書いた「はじめての正規表現入門(超初心者向け)」という記事を読んでみてください。
使えるようになると世界が変わるので、エンジニアじゃなくてもマスターすることをお勧めします。
通信やブラウザ関連
だいぶ長くなってきたのと、だんだん知ってる領域から遠くなってきたので、ここからはさらに概念的な感じが加速します。
URL・パス
URL はインターネット上の住所で、プロトコル・ドメイン・パス・ファイル名で構成されます。
ざっくり、以下のような感じです。
| プロトコル | http:// とか https:// の部分。通信の種別 |
| ドメイン | 〇〇.com とかの部分 |
| パス | 自サイト内の置き場所。ドメインの後ろの/〇〇/の部分 |
| ファイル名 | 〇〇.html や 〇〇.jpg |
また、HTML などサイト内からファイルの置き場を指定するパスの書き方については一般的に以下の 3 種類があります。
(興味のある人は、それぞれの名前でググってみてください)
| 絶対パス | URL 通りそのまま書く |
| 相対パス | 今読み込まれているファイルのディレクトリ(階層)を起点に書く |
| ルート相対パス | サイトのルート(/)を起点に書く。個人的に一番好き |
IP アドレス
これもインターネット(またはネットワーク)上の住所です。分かりづらいですね。
URL(ドメイン)が〇〇町〇丁目のような表記で、IP アドレスが緯度・経度のような表記というイメージです。
それを相互に変換してくれるのが DNS(ドメイン・ネーム・システム)です。
私もそれ以上のことは良く分かっていないので、このあたりまで知っていれば問題ないと思います。
サーバー
ネットワークを通して情報を提供(サーブ)する機械です。
自前で用意することも、レンタルすることも可能で、実際の機械だけじゃなく、クラウド上に仮想サーバーとして構築することもできます。
ただ、機械である以上は性能の限界があり、アクセスが多すぎるとダウン(落ちる)したりします。
よく分からないうちは、Wi-Fi の向こう側にいる情報の発信者と考えればだいたい大丈夫だと思います。(詳しい人に怒られそう)
クライアント
サーバーに対して、受信側です。ほとんどの場合はブラウザやスマホのアプリのことで、ネットワークプリンタやスマートスピーカーなどもクライアントです。
サーブ(提供)される側なのでクライアントなんだと勝手に思っています。
リクエスト・レスポンス
クライアントがサーバーにコンテンツ等を要求するのがリクエストで、反対にサーバーがクライアント側に応答するのがレスポンスです。
Web ページのリクエストの際に、サーバーが返すものの 1 つがステータスコードと呼ばれる「200」とか「404」というレスポンスです。
リクエストが多すぎてレスポンスが重たくなる等、ほぼ言葉のイメージ通りの使い方をする用語です。
ユーザーエージェント
クライアントがサーバーにリクエストを送信する際に、一緒に送る情報(文字列)の 1 つです。
その文字列には色々な情報が詰まっているのですが、例えば iPhone ならユーザーエージェントにも "iPhone" と書いてあったりするので、「どういう端末やクライアントがアクセスしてきているか」の判定に使われることが多いです。
User-Agent と書くので、UA と略す場合もあります。
パース・レンダリング
すごくざっくり書くと、パースは HTML の解析で、レンダリングは CSS や Javascript も含めた描画(ユーザーがブラウザで見るのと同じコンテンツ)です。
以前書いた「SEO 初心者向け Google 検索の仕組み」という記事では、ここまでで説明を断念したのですが、今回は少しだけ補足します。
GTM においてはページビュー トリガー発火のタイミングとして「DOM Ready」や「ウィンドウの読み込み」が存在します。
ブラウザがパースを完了して DOM が利用できるようになるのが「DOM Ready」で、CSS・JavaScript や画像ファイルを読み込んでレンダリングし終わったのが「ウィンドウの読み込み」です。
その間には各外部ファイルへのリクエストが発生しています。
また、PageSpeed Insights のようなページ読み込み速度計測ツールでは、上記のようなステップの中で指標を決めて、そこまでにかかった時間を評価します。
このように、ブラウザがパースを開始してからレンダリングを完了するまでのステップを意識することで、良く分からない指標の意味が何となく理解できるようになります。
詳しい解説については以下の記事が参考になると思います。(前者はだいぶ古いので、基本構造の部分の参考までに)
キャッシュ
Web の文脈で言うキャッシュには大きく分けてブラウザキャッシュとサーバーキャッシュの 2 種類があります。
ブラウザが描画を完了するまでには外部ファイルの読み込みがあるのは先ほど説明しましたが、毎回それを行うと通信量が多くなり表示に時間もかかります。
そのためにブラウザが過去に取得したリソースを保持してそのまま使おう(使わせよう)とするのがブラウザキャッシュです。
一方でサーバーキャッシュとは、リクエストに対してデータベース等にアクセスし生成した結果を保持しておくことで、同様のリクエストに対してレスポンスの負荷を減らし、高速に応答するために行うものです。
紛らわしい用語としてCDN(Content Delivery Network)で利用されるキャッシュサーバーがありますが、これはキャッシュした結果を配信する専用のサーバーのことです。
CDN
話題に出してしまったので、CDN にも触れます。
以下の図のように、キャッシュが生成されている場合にはリクエストを肩代わりしてくれる存在です。
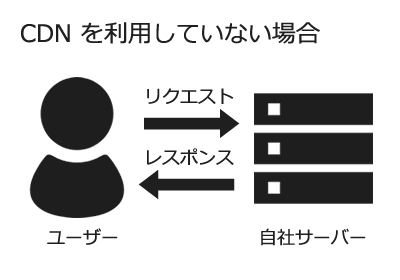
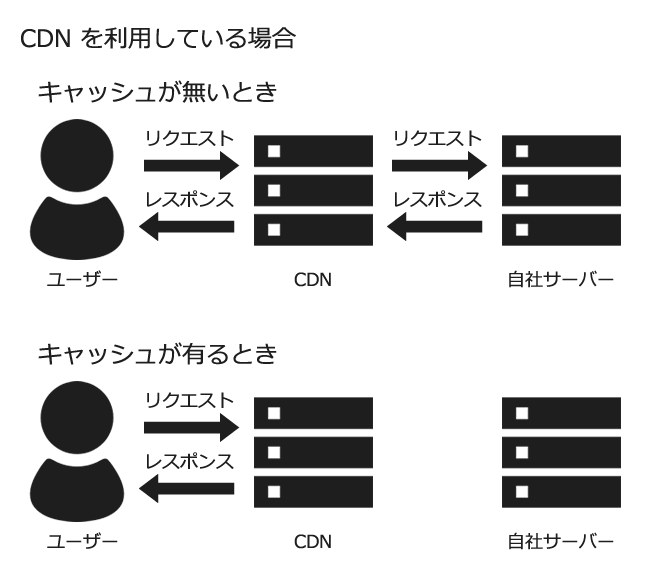
キャッシュからの配信はとても便利ですが、その更新のサイクルを管理する手間が増えるのと、リアルタイムに更新しなければいけないコンテンツの場合には注意が必要です。
Cookie
Cookie(クッキー)は Web サイトがブラウザに保存できる情報の 1 つです。
任意の名前で好きな値を保存することができます。
(保存できる容量はブラウザにより決まっています)
Web サイトは、リクエストに応じてレスポンスを返すのでユーザーという概念を持ちません。
そのため、例えば会員制サイトのログイン状態やサイト内の行動の把握(アクセス解析や広告コンバージョン)のために利用されることが多いです。
サイト運営者側の用語として、ブラウザに Cookie を保存することを「Cookie 食わせる」と言います。
(お菓子のクッキーにちなんで)
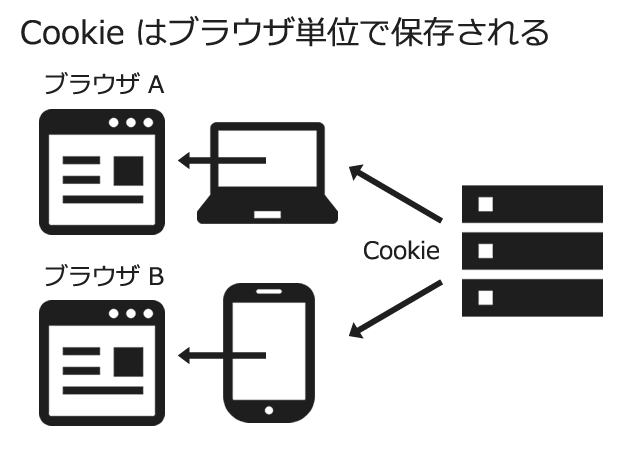
ブラウザの単位で保存されているので、例えば PC とスマホには異なる Cookie が保存されています。
ただ、ログイン機能があるサービスなどは、ログイン後にブラウザの Cookie とログイン情報を照らし合わせて同一ユーザーと判定可能にできます。
ブラウザ・端末をまたいでサービスを利用できるのは便利なのですが、その一方でログイン情報や行動履歴がブラウザに保存されてしまうので、プライバシーやセキュリティの懸念が起きます。
(対策としては、不特定多数が使うブラウザではシークレットモードを利用するなど)
特に広告の文脈で話題になることが多いのですが、そのあたりの詳細は以下の記事で良くまとまっていますので、興味のある方は確認してみてください。
検索の話だと、Googlebot が Cookie を利用しないのも有名な話ですね。
(そのページに初めて、直接訪れたユーザーと同じ振る舞いをします)
なので、Cookie を使ってパーソナライズしたコンテンツを表示している場合には、自分がブラウザで見ているのと違ったコンテンツを Googlebot が見ている可能性を考慮しなければいけません。
同期・非同期
何らか処理を行う際の段取りのことです。
ブラウザの処理を例にあげると、基本的に書いたタグを上から解析していきます。その際に、見つけたリソース(外部ファイル)にリクエストを送っていきます。これを同期的な処理と言います。
ただ、同時にリクエストできる数には制限があるので後続のリソースは先行するリソースのレスポンスとダウンロードを待たなければ読み込まれません。
もしページの見た目に関わるリソースが後続のリクエストになってしまった場合、画面が真っ白のままということもあります。
それに対して、非同期処理では最初の画面描画に必要なリソース以外をユーザーの画面操作や一定時間の経過などで取得します。
ユーザーに高速な体験を提供できる一方で、ユーザーの画面操作が無いと読み込まれないリソースについては Googlebot に読み込まれない等の弱点もあります。
どちらを何に利用するかは、用法・用量の注意が必要です。
また、Cookie やログイン情報などに応じてユーザー個別の情報を表示するようなサイトでキャッシュを利用する際に、ユーザーごとに異なる情報だけ非同期通信で取得して出し分けるという使い方もします。
API
アプリケーション・プログラミング・インターフェイスの略です。カッコいいですね。
ざっくり言うと、外部との通信を受け付けて動作する特定のプログラムのパッケージです。
通信の際には特定のフォーマットのリクエストを送信して、その応答結果を受け取って利用します。
また、そのリクエスト送信を「叩く」と言います。
「このデータ、API 叩いて取ってきた」などというように使うので、物騒ですね。
実務関連
本番環境・ステージング環境・開発環境
商用のサイトを運営している場合は、ほぼ必ずこういう環境があると思います。
それぞれの違いは、簡単に書くと以下のような感じです。
| 本番環境 | プロダクション環境とも呼ばれる。お客さんが見ている環境 |
| ステージング環境 | 検証環境とも呼ばれる。社内でみんなが新機能とかを確認する環境 |
| 開発環境 | エンジニアがそれぞれ持っている環境。好き勝手できる |
人月・人日
作業工数の管理や見積もりの際に使う用語です。
1 人月は 1 人がフルタイムで取り組んだとして 1 ヶ月かかるという意味ですが、よくそのまま 1 ヶ月と勘違いされます。
普通は他の案件や打合せ、メールのやり取りなどもしているので、フルタイムでその案件のみに取り掛かれることはありません。
その点を勘違いして「1 ヶ月って言ってたじゃないですか!?」などと言ってしまうと、エンジニアに嫌われてしまいますので注意してください。
要件
Web の文脈での要件(ようけん)とは、システムなどが満たすべき条件のことです。
例えば、ユーザーに「ファイルの保存とダウンロード」という機能を提供したい場合、以下のような要件を考えないといけません。
- アップロードできるファイル(形式・容量)
- アップロード時に他に保存するもの(日時など)
- ダウンロードの形式(個別?圧縮?)
- 利用できるユーザー(全員?会員?)
実際にはもっと細かい粒度の要件もあるので、機能の企画者には想像しづらい点も多いです。
そうした部分をエンジニアとすり合わせていくことを「要件定義」と言います。
ワイヤーフレーム・モックアップ
要件定義の際に、見た目や動きのイメージを共有するために作られるものです。
個人的には静的な画面イメージまでがワイヤーフレーム、遷移なども確認できるのがモックアップという使い分けかなと思っています。
最近だと Adobe XD など、わざわざ HTML で作らなくても画像の部品をペタペタ貼って矢印を繋げるだけで画面遷移を作れるツールもあるので作りやすいです。
実装
要件が固まったらエンジニアが機能を実際に組み込むことを実装(じっそう)と言います。
現場では、その過程を「実装していく」とか「実装中です」と呼びます。
実装は以下の流れで行われます。
1. 開発環境でエンジニアが試行錯誤
↓ ↓ ↓
2. ステージング環境に展開して検証
↓ ↓ ↓
3. 本番環境に一般公開
データベースから情報を取得したり数々の条件分岐を駆使して機能を実現していくため、要件に漏れがあったり認識違いがあると手戻りが発生し、見積もりした工数に影響を与えたりします。
ただ、実装まで進まないと依頼者も実装者も見えづらい点もあるので、この段階で何か違和感を感じたらすぐに共有したほうが良いです。
こうした、目に見えてなかった隠れた要件のことを「非機能要件」と言います。
まとめ
簡単なところから始めて難しい用語に進んだので、後半は文字ばかりになってしまって恐縮です。
この記事を書いた背景は、技術まわりのことを勉強していたときに用語を調べようと思って MDN のような解説サイトを見ても意味が分からなかった経験が多くあるからです。
後になって何となく概念が分かると読めるようになってくるのですが、その概念を説明してくれるサイトがなかなか無かったので、当時はとても苦労しました。
SEO の話題も技術関連の用語が多く登場するので、同じように悩む方にとって少しでも入り口の役割を果たせたら良いなと思います。
それでは、またいつか!